復雜語(yǔ)言
 在常用的語(yǔ)言中�����,如拉丁語(yǔ)系(英文���、法文)及東亞語(yǔ)系(中文����,韓文和日文)����,一個(gè)字符無(wú)論出現在詞的什么位置���,它的形式是固定的�����。而有一些語(yǔ)言則不是這樣��,在這些語(yǔ)言中一個(gè)字符存在多個(gè)字形����,當字符在詞中的位置不同時(shí)(例如�����,位于詞首���,詞中和詞尾或獨立)��,需要選擇不同的字形來(lái)表示��,這些語(yǔ)言統稱(chēng)為復雜語(yǔ)言���。常見(jiàn)的復雜語(yǔ)言有蒙古文�����、藏文��、阿拉伯文等���。下圖中是編碼為1820(16進(jìn)制)蒙文字符的變化形式����。
在常用的語(yǔ)言中�����,如拉丁語(yǔ)系(英文���、法文)及東亞語(yǔ)系(中文����,韓文和日文)����,一個(gè)字符無(wú)論出現在詞的什么位置���,它的形式是固定的�����。而有一些語(yǔ)言則不是這樣��,在這些語(yǔ)言中一個(gè)字符存在多個(gè)字形����,當字符在詞中的位置不同時(shí)(例如�����,位于詞首���,詞中和詞尾或獨立)��,需要選擇不同的字形來(lái)表示��,這些語(yǔ)言統稱(chēng)為復雜語(yǔ)言���。常見(jiàn)的復雜語(yǔ)言有蒙古文�����、藏文��、阿拉伯文等���。下圖中是編碼為1820(16進(jìn)制)蒙文字符的變化形式����。

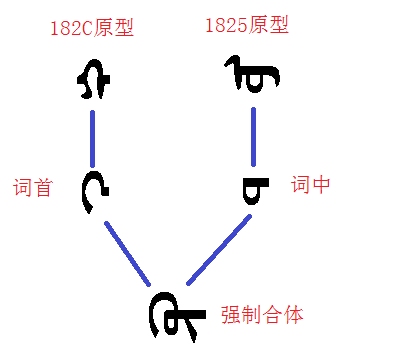
除此以外��,在一些語(yǔ)言中����,還有強制合體的要求�,即當某個(gè)規定的模板(多個(gè)字符連續)出現時(shí)�,需要用一個(gè)其它的字符替換����,例如當出現182c,1825且位于詞首時(shí)�,不僅要根據其中詞中的位置進(jìn)行變換�,還要執行強制合體變換��。如下圖中所示:
變換規則和字體支持
每種語(yǔ)言都有自己的變換規則��,字體創(chuàng )建者在創(chuàng )建字體時(shí)���,可以使用OpenType提供的技術(shù)把變換規則嵌入在字體文件中�����,以便客戶(hù)在使用過(guò)程中根據規則選擇正確的變換�。
特點(diǎn)
通常在將復雜語(yǔ)言文字生成PDF文件時(shí)�����,只能通過(guò)打印的方式實(shí)現����,排版軟件根據字體中的變換規則對字符進(jìn)行了替換(在Windows平臺上可以使用unscripe技術(shù)����,在linux平臺上可以使用pango和IBM提供的icu庫實(shí)現��。但是打印生成的PDF文件通過(guò)無(wú)法復制��,主要是因為打印僅能提供字形的變換����,不能提供編碼的變換��。而我們的開(kāi)發(fā)包不僅提供字形變換�,同時(shí)也進(jìn)行了編碼的變換�����,使得生成的PDF文件是支持文本復制的�����。
示例
[
文本文件][
生成的PDF文件]