PDF可查詢(xún)化
 在紙質(zhì)圖書(shū)數字化的初期���,為了盡快推出產(chǎn)品�,很多數據提供商直接用掃描后的圖像生成PDF文件�,并沒(méi)有做文字識別�����,這樣的電子書(shū)僅能滿(mǎn)足瀏覽的需要����。
在紙質(zhì)圖書(shū)數字化的初期���,為了盡快推出產(chǎn)品�,很多數據提供商直接用掃描后的圖像生成PDF文件�,并沒(méi)有做文字識別�����,這樣的電子書(shū)僅能滿(mǎn)足瀏覽的需要����。
由于這些PDF文件僅包含圖像數據���,沒(méi)有相應的文字�,無(wú)法對其進(jìn)行搜索�。而利用搜索功能查找感興趣的內容是現今大部分客戶(hù)最常用的手段����,所以對這些數據進(jìn)行二次加工����,使其能滿(mǎn)足搜索需要是必然趨勢���。
PDF可查詢(xún)化方案正在在這樣的背景下設計和開(kāi)發(fā)的���,它將PDF中的圖像提取出來(lái)����,交給成熟的OCR引擎進(jìn)行文字識別���,并對識別結果進(jìn)行整理���,最后通過(guò)版面還原達到文字與圖像內容一致的效果(也就是雙層PDF文件)��。示意圖如下:
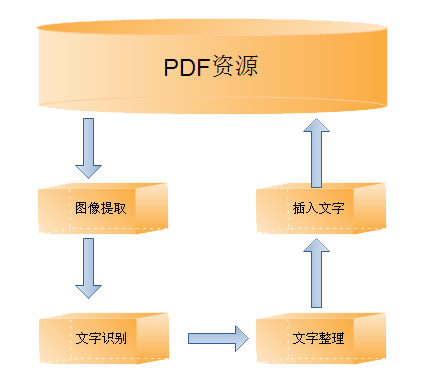
技術(shù)優(yōu)點(diǎn)
- 不需要折分已有的PDF文件�,而是在現有的PDF文件基礎上操作��;
- OCR引擎可以根據需要靈活選擇���,中文可以選擇漢王或者文通���,外文可以選擇FineReader�;
- 自動(dòng)處理過(guò)程中���,不需要人工干預�����;
- 可以對已處理過(guò)的文件進(jìn)行重新處理��。一旦OCR引擎升級并且識別質(zhì)量有所提升后�,可以對文件進(jìn)行重新處理�。
- 處理速度極快���,處理過(guò)程的90%以下時(shí)間由OCR引擎消耗�。